2006年,Hinton提出的“貪婪算法”訓練多層自編碼器引領了一批專家去研究深度神經網絡,包括LeCun和Bengio等。深度神經網絡之所以取得巨大成功,筆者認為其最核心算法改進在于采用了一類簡化的激活函數,即規則化線性單元(rectified linear unit,ReLU)。由圖3可知,ReLU本質上是分段線性函數y=max(0,x)。類似ReLU的激活函數事實上早在1975年即被提出[5],但是在1980年代被Sigmoid等具有良好非線性、連續可導、梯度計算復雜度低等優點的激活函數全面取代。一直到2009年,LeCun團隊[6]在研究深度神經網絡時,發現采用類ReLU的分段線性激活函數是實現對深度網絡端到端訓練的關鍵因素。2011年,Bengio團隊[7-8]研究得到結論:深度神經網絡最適合用ReLU作為激活函數,給出的理由包括ReLU與人腦神經元的相似性,因為神經元對某些輸入完全沒有反應,而對一些輸入的反應呈單調關系,每一時刻處在激活狀態的神經元總是稀疏的。這些工作為2012年Hinton團隊[3]首次采用深度卷積網絡贏得ImageNet 挑戰賽奠定了理論基礎。
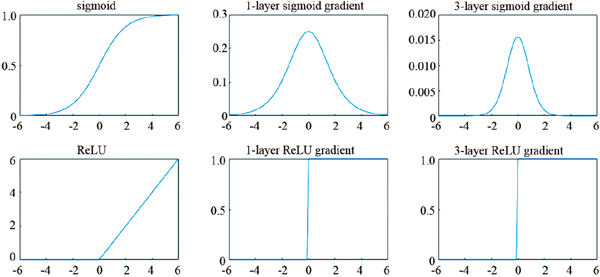
圖3 2種激活函數(Sigmoid,ReLU)及其單層、多層梯度比較
Fig. 3 Two types of activation function (Sigmoid, ReLU) and their single-layer, multi-layer gradients
關于ReLU優點,圖3給出一種簡單的解釋,即其梯度在多層網絡后向傳播時能保持穩定,不像Sigmoid的梯度在累乘后容易達到飽和。關于ReLU的理論研究在2012年后還在繼續,例如2015年LeCun團隊[9]證明了深度神經網絡的損失函數中的局部最小值均為較優解,且很容易被隨機梯度下降算法找到,由此在理論上,它解釋了深度神經網絡取得巨大成功的一個主要原因。
可以看出,深度神經網絡的本質是采用很多層嵌套的非線性函數來擬合海量的數據,監督學習即擬合高維數據空間中的一個曲面,而非監督學習如生成網絡則擬合一種分布。至目前為止,真正解決實際應用問題的深度學習技術,無論在網絡結構上有各種各樣的創新,或者在訓練優化算法上有各種各樣的設計,都逃脫不了一個模式,即用海量的訓練數據擬合一個包含海量未知數的復雜多層網絡。
因此,筆者完全贊同圖靈獎獲得者Judea Pearl的觀點:無論深度學習技術取得多大成功,各種相關研究多么五花八門,我們還沒有突破其曲線/曲面擬合的本質[10]。不少學者已經開始反思深度學習面臨的困境,由于其背后基礎理論積累不足,深度學習技術很快就陷入一個瓶頸期。現在的深度學習相關技術過于簡單,以致可以完全被計算機掌握,由于各種工具箱的出現使得絕大多數人可以輕易掌握深度神經網絡應用技能,絕大多數人掌握這些技能后便快速陷入調參數、調結構的瓶頸。顯然,這本身就是一份機械的工作,可以被人工智能取代。果然,谷歌公司于2018年初推出的AutoML工具即扮演了調參的角色,使得一大部分應用深度神經網絡的人被深度神經網絡取代。谷歌公司最新開發的AlphaGo Zero新版圍棋程序也證明了靠機械的搜索來獲得較優解決方案的工作也可以被取代。可以預見,更多的在研究網絡結構和優化算法的科研人員也將被取代。深度學習技術的出現,預示著缺乏創造力的機械工作將會被取代。
因此,深度學習出現的意義首先是很好地利用了數據資源優勢,實現超強擬合能力,解決各個領域的實際應用問題。其次它引發了人們對于人工智能技術的廣泛關注,引領了一個大力研究智能科技的時代。然而,深度學習的超強擬合能力導致人們的期望過高,如果智能科學的基礎理論遲遲沒有突破,很快深度學習或人工智能就會跟不上人們對它的期望。
1.2 智能科學的誕生
人工智能深度學習技術的廣泛應用必將要求智能科學的誕生。智能科學應是一門區別于自然科學和社會科學的嶄新學科。它的誕生不僅僅與深度學習技術爆發有關,而且與腦科學、認知科學、理論神經科學、數據科學的發展密切相關,智能科學甚至還與一般自然科學和社會科學相關,這些學科是智能科學的前奏和基石。
智能科學是人工智能背后的基礎科學,人工智能是建立于智能科學之上的一門應用學科。首先需要關心的是人工智能需要什么樣的科學支撐。社會學家將廣義人工智能分為3類:弱人工智能和強人工智能和超人工智能。弱人工智能是指擅長某一方面的人工智能,現階段發展的人工智能就是弱人工智能。強人工智能指的是與人類比肩的人工智能,人類能做的事情它都能做。超人工智能就是科幻世界中經常出現的智力超越人類的人造機器。人工智能的目標可以歸納為4點——像人一樣行動、像人一樣思考、合理地思考、合理地行動。如果要使機器能像人一樣思考的話,必須先弄清楚人類是如何思考的。這本身就是一件復雜而有趣的工作。有3種辦法可以完成這項任務:通過內省——反思人類的思維方式;通過心理實驗——觀察被測對象,然后總結;以及通過腦成像——觀察大腦的活動規律。然而,直到今天,人類對于自己大腦的運作原理以及人類思維等的認識仍然不足,認知科學還有諸多問題有待解決。
當前深度網絡的巨大應用成功僅僅發源于人們對于視覺神經網絡的理解和仿生。大腦和智能作為至今人類還沒有研究透徹的領域,不斷引起了科技界,乃至工業界和政府部門的重視。系統的腦科學研究主要分為自底向上的生物學研究和自頂向下的理論神經科學或認知科學研究,神經生物學通過生物觀測實驗手段從微觀層面開始,不斷向上積累基礎知識,試圖理解整個大腦的工作機制,例如通過神經元細胞切片的觀察,一直到宏觀尺度的大腦活動功能核磁共振(fMRI)成像等,神經生物學研究目前無法徹底理解大腦工作機制,主要局限于對活體大腦實時活動的微觀觀察手段的缺乏,近年來發展的熒光標記高分辨率光學成像技術將是該領域下一個突破口。理論神經科學或認知科學研究通過對人類宏觀行為的理解建立數學理論模型以圖仿制大腦智能。理論神經科學仿照牛頓物理學首先從數學上對大腦工作機制進行建模,通過假設的基本規律來逐步解釋更復雜的大腦工作機制,與生物學手段比起來,理論神經科學的研究一直停滯不前。實驗觀測和理論建模必須有效結合,才能得到可靠的進展。例如通過觀測發現的脈沖時間相關可塑性(SDTP)機制被認為是記憶和學習的神經化學基礎,對于神經網絡模型的構建具有重要推動作用。除了系統的腦科學研究,目前提及最多的是更接近應用層面的類腦人工智能算法(即深度學習)及其實現(即神經網絡芯片),以及機器人外圍技術(如機械骨架、仿生材料)。當前類腦人工智能算法與真正意義上的神經生物學的結合不夠緊密,這將是下一代人工智能發展的方向之一。而機器人外圍技術由于其在工業生產、家庭護理、國家安全等領域的重要應用得到重視,在人工智能技術的推動下,機器人可以實現的功能已快速接近以前只有在科幻世界中才出現的場景。
美國、歐盟、中國均已經或即將推出各自的大腦研究計劃和人工智能戰略,在神經生物學、類腦人工智能技術等方面開展研究。解開大腦的奧秘是開啟未來智能世界的關鍵,是未來科技發展的戰略制高點,誰掌握人工智能,誰將成為未來核心技術的掌控者。
人工智能及其相關技術日新月異,每周都有相關突破性進展報道。但是如前論述,深度學習本質即為超強函數擬合,其技術紅利可能將很快被用盡。顯然,目前的人工智能依舊處于弱人工智能范疇,走向強人工智能和超人工智能的道路依舊一團迷霧。在這個過程中,需要先解開大腦思維的奧秘,發展系統的智能科學。就像看到鳥的展翅飛翔,有了人類飛行的萌芽,但要發明飛機,則要發展現代航空力學與航空工業。
多名學者針對深度學習的火爆現象進行了冷靜思考,并提出智能科學的研究建議。深度學習的引領人物也不停在反思,Hinton等[11]在深度學習進入火熱的現象后,一直在思考,最近提出要推翻后向傳播梯度下降的算法,認為人腦不是靠梯度下降學習,提出“膠囊網絡”的新概念。LeCun[12]針對機器學習的發展也提出無監督學習與預測學習是機器學習的一個大方向。
此外,深度學習也受到來自機器學習其他領域學者的質疑,比如谷歌公司的Rahimi[13]在第31屆神經信息處理系統大會(NIPS 2017)上公開將當前深度學習的研究比喻為“煉金術”,其本意就是批評當前大量的深度學習研究僅僅浮于網絡結構和參數的不斷調整嘗試上,而沒有試圖建立一門基于嚴謹、周密、可驗證的理論之上的科學。
正如人人會做的釀酒術,并不能容易產生近代化學一樣。LeCun認為:工程總是先于理論,就像望遠鏡先于光學、蒸汽機先于熱動力學、計算機先于計算科學等。對于此,麻省理工學院Poggio[14]則認為當前深度學習太依賴于數據,應該回歸到理解人類智能上來,即腦科學和神經科學,比如首先解釋人腦智能是如何產生的這樣的根本科學問題。
2011 年圖靈獎獲得者、貝葉斯網絡的先驅JudeaPearl[10]最近發表論文闡述了機器學習理論的可能發展方向,認為當前深度學習的本質即函數擬合,其所關聯的數據科學也只跟數據有關并沒有科學。Pearl認為強人工智能的正確途徑是引入因果關系,他將其分為關聯(association)、交互(intervention)和想象(counterfactu?al)3個層面(圖4[10])。當前深度學習僅停留在關聯的層面,在交互的層面需要引入互動并觀察其因果關系,而在想象層面則需要具備邏輯推理能力。最后,他提出應采用他本人發明的用于描述因果關系的貝葉斯網絡等數學工具來研究下一步的強人工智能。

圖4 Pearl的3層因果關系
Fig. 4 Pearl's three layers of casual relationship
加州大學洛杉磯分校朱崧純[15]對人工智能從現狀、任務到構架與統一進行了系統的闡述。他將人工智能學科分為6個方向:計算機視覺、自然語言理解與交流、認知與推理和機器人學、博弈與倫理和機器學習。他對于人工智能的一個觀點也是與數據依賴性有關,認為人工智能不應該依賴大量數據,更應該關注人腦內在因素。認為智能科學是牛頓與達爾文理論體系的統一,提出應該把面向應用的人工智能變成智能科學。他提出一個很好的觀點:“物理學把生物的意志排除在研究之外,而這正好是智能科學要研究的對象。智能科學要研究的是一個物理與生物混合的復雜系統。智能作為一種現象,就表現在個體與自然、社會群體的相互作用和行為過程中。我個人相信這些行為和現象必然有統一的力、相互作用、基本元素描述。”這是筆者所了解到的對智能科學最深邃的見解之一。
1.3 智能科學與物理智能
智能科學是智能時代所必須的支撐基礎科學,它的內涵遠不止當前的深度學習技術。智能科學應以人腦為支點,研究人與自然世界、人與人類社會的多體問題。但智能科學不能是孤立的研究人腦的科學。人腦是進化和后天學習的產物,生物進化給予人類一套可塑的神經組織,通過人與世界和社會的交互才形成了人類智能。人腦本身的結構組成和工作機制離不開外界對它的影響。可以想象一個初生的嬰兒若一直孤獨地生存在太空中,不與任何物質或信息交互,則不可能具備人類智能。所以說,人類智能是外在世界對人腦施加作用后所產生的反作用,外在世界與人腦智能是一雙對偶問題。現有科學已經對外在世界建立較為成熟的理論體系。
因此智能科學應是一門以人腦為中心,研究人腦與自然世界相互作用、人腦與人腦相互作用,人腦與人類社會相互作用的學科。它不僅依賴于一套能描述人腦原理的數學理論,還需結合用于描述自然世界單體問題的自然科學和用于描述人類社會單體問題的社會科學。
按這一觀點將人工智能分為下面4個階段。
第1個階段研究對象為人類智能的大腦原生組織結構,即自然進化賜予人類的可塑神經網絡,借助于腦科學與計算神經科學等,發展一套可以建模大腦原生組織結構的數學工具,可以稱之為數學智能。這一階段的目的是用數學和計算工具描述和模擬初生嬰兒大腦的通用組織結構和通用學習算法。
第2個階段研究對象為外在物理世界加到人腦的“外力”導致在人腦中產生的“應力”,即人腦與物理世界交互后學會的適應物理世界并在其中生存的能力,可以稱之為物理智能。物理智能即能適應客觀世界的人工智能,如機器人。構造物理智能必須依賴數學智能和物理學。人類建立起來的強大的物理學理論體系有助于構造強于人類的物理智能,即比人類更適應物理世界的智能體,本文第2節討論的微波視覺即屬于這一范疇。物理智能可以推廣到廣義的自然智能,即研究能夠適應各種自然科學現象的人工智能。
第3個階段研究對象為他人或社會對于人腦的“外力”與所產生的“應力”,即人腦如何學會與他人相處、如何在人類社會中適應和生存的能力,可以稱之為心理智能,或廣義的社會智能。這個階段研究智能與智能之間的高階相互作用,也可稱為高階智能;則物理智能屬于一階智能,因為其研究范疇只涉及單個智能體。